

Il Machine Learning può essere sintetizzato come la capacità della macchina (e quindi del computer) di apprendere automaticamente, senza essere stata precedentemente programmata. Questa definizione è stata coniata nel 1959 da Arthur Samuel, esperto statunitense di intelligenza artificiale e videogames, quando ideò un algoritmo capace di analizzare la posizione della pedina nel gioco della dama, in ogni istante della partita. Questa funzione provava a calcolare la possibilità di vittoria per ogni lato nella posizione attuale, agendo di conseguenza. Il programma liberamente sceglieva le sue mosse basandosi in modo da ottimizzare le proprie azioni, assumendo che l’avversario agisse e ragionasse nel medesimo modo.
Tom Mitchell nel 1998, creò una definizione più operativa del Machine Learning asserendo che un Software di Machine Learning impari dall’esperienza (ad esempio il gioco della dama) rispetto al compito affidato (giocare a dama con le sue regole) e alla misura delle prestazioni (di quelle della probabilità che il programma vinca la partita successiva), se la sua prestazione (del compito di giocare a scacchi in questo esempio) misurata nella prestazione (probabilità che il programma vinca) migliora con l’esperienza (in questo caso di giocare a dama).
Da qui nasce il concetto di come il Machine Learning permetta ai computer di imparare dall’esperienza e di come le prestazioni migliorino dopo il completamento di una azione (anche errata! Dagli errori si impara …).
In ambito informatico, non si spiega alla macchina “come fare” (altrimenti ripeterebbe semplicemente gli stessi errori e ragionamenti umani) ma le si forniscono dei set di dati che vengono elaborati tramite algoritmi con cui la macchina sviluppa una propria logica, l’attività da fare e il compito richiesto (trova tutti i cani all’interno di un data base di 1000 immagini).
Il Machine Learning può essere supervisionato o non supervisionato. Nel primo caso viene fornito alla macchina un set di dati e gli si chiede di identificare una regola per la quale il dato di esempio di ingresso è correlato al dato di esempio di uscita (quindi gli si fornisce un set di dati in qualche modo “congiunti” senza svelargli la regola di associazione e che lo aiuteranno a sviluppare una propria logica e un set di dati sui quali applicarla). Nel secondo caso, quello non supervisionato, viene fornito solo il set di dati senza alcuna indicazione del risultato desiderato.
Perché si adottano queste modalità così differenti? Perché nel primo caso facciamo sì che la macchina lavori su una grandissima mole di dati velocemente (poniamo il riconoscere in un database di miliardi di foto, quelle che ritraggono un cane e seperarle dal resto), sapendo cosa andiamo ad indicargli e cosa vogliamo che elabori, nel secondo caso vogliamo che la macchina risalga a schemi e modelli nascosti e che identifichi negli input una struttura logica “personale”.
È normale che nel secondo caso la macchina possa andare a elaborare, senza regole prestabilite, anche azioni che si discostano molto da ciò che desideriamo come obiettivo. Nel gioco della dama, ad esempio, il sistema impara giocando (e quindi è guidato dalle regole) e impara dagli errori commessi e dal raggiungimento degli obiettivi, migliorando le proprie prestazioni. Quando la macchina esegue un’azione che la porta a raggiungere l’obiettivo che abbiamo in mente viene “premiata”. Questo premio, in informatica, si chiama apprendimento per rinforzo. Altro metodo per aiutare la macchina, è un sistema ibrido fra un set di dati di esempio incompleti e solo alcuni di questi sono dotati di un output. Questo permette di identificare regole e funzioni per la risoluzione di problemi, modelli e strutture, dati utili al raggiungere determinati obiettivi dando alla macchina la facoltà di scegliere con un apprendimento semi-supervisionato.
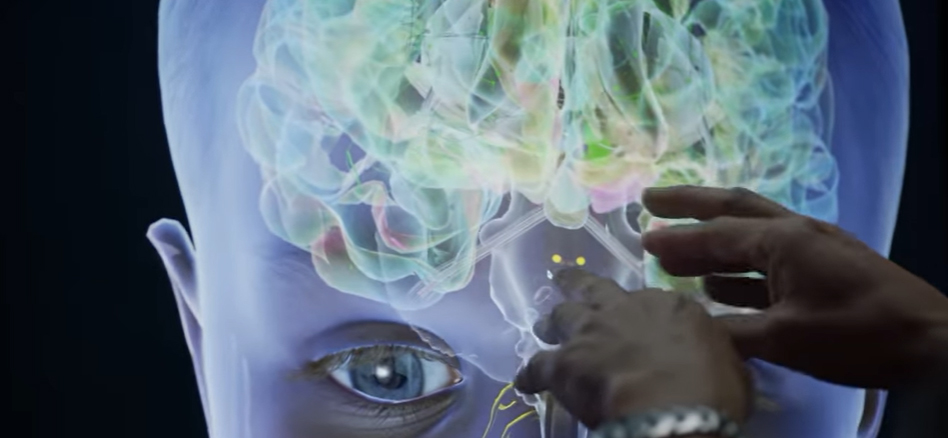
Per quanto riguarda le applicazioni, possiamo pensare a tutte quelle azioni che quotidianamente eseguiamo, senza pensare di star utilizzando il Machine Learning. Se pensiamo all’utilizzo di un motore di ricerca, inserendo una parola questo crea un elenco di soluzioni al nostro quesito. Ciò è effetto di un algoritmo con apprendimento non supervisionato. Il filtro anti spam delle mail impara da tutte quelle mail che noi segnaliamo come spam, o che non vogliamo leggere, e non le ripropone confinandole in una cartella nascosta. In ambito medico, la ricerca scientifica utilizza gli algoritmi per effettuare previsioni sempre più accurate per prevenire lo scatenarsi di epidemie, effettuare diagnosi preventive di malattie o per prevedere i decorsi di cronicità. Quando acquistiamo qualcosa dai più comuni e-commerce, questi analizzano il nostro comportamento anche su altri siti, le preferenze delle nostre ricerce, i siti che navighiamo nel web, proponendoci offerte derivanti le nostre preferenze e ricerche. Siri, Alexa, Google, riconoscono la nostra voce e inizialmente ci chiedono di dire delle parole per imparare il nostro modo di pronunciarle. Rispondono alle nostre richieste vocali e sono in grado di effettuare azioni per conto nostro (accendono luci, leggono notizie, ricordano appuntamenti e ci propongono occasioni da acquistare secondo le nostre preferenze). Acquistando un auto con un optional di guida adattiva, l’auto segnalerà all’utente se è meglio effettuare una pausa dopo molte ore di guida, frenerà per noi se un pedone ci taglia la strada, rientrerà in carreggiata se rileva che non rimaniamo all’interno della nostra corsia, alzerà i fari abbaglianti quando nessuno è sulla strada e sta calando il buio. Nel campo della ricerca, moltissimi scienziati utilizzano sistemi di algoritmi di intelligenza artificiale in grado di controllare foto scattate (a prescindere dall’origine) per riconoscere i segni unici degli animali, tracciare gli habitat utilizzando le coordinate GPS fornite da ciascuna foto, stimare l’età dell’animale e rivelarne il sesso. Basti pensare che dopo una campagna fotografica del 2015, si è riusciti a stimare che esiste un rischio di estinzione delle zebre di Grévy (Kenya) a causa dei troppi attacchi ai cuccioli da parte dei leoni, spingendo i funzionari locali a proteggere quindi questa specie. Infine Medici Specialisti, hanno impiantato due chip, uno nella corteccia sensoriale che controlla il tatto e l’altro nella corteccia motoria che controlla il movimento, nel cervello di un quadriplegico per far si che questo fosse in grado di controllare il braccio robotico al quale è stato connesso. Con i pensieri la Nathan era in grado di muovere il braccio robotico e di avere la percezione del tatto come se questo fosse effettivamente parte del suo corpo. (Nathan Coperland – Pittsburgh)
Possiamo così asserire che l’intelligenza artificiale e il Machine Learning è entrato a far parte delle nostre vite, anche se, probabilmente, non ce ne siamo accorti e regolarmente lo utilizziamo nella nostra quotidianità e ci viene in aiuto nella risoluzione di problematiche di cui prima non eravamo in grado di porre soluzioni.
















































































































{kind=link}